
Pandasの使い方を確認します。
今回は複数行・複数行のデータの取得方法についてです。
複数行列の取得
複数の行と列を取得
複数の行と列を指定してそのデータを取得します。
ここでは、列名が「年月日」・「時刻コード」の2列の中から、0行目と4行目のデータを取り出してみます。
|
1 2 3 4 5 |
import pandas as pd df = pd.read_csv('ファイル名') #ファイル名の部分は、ファイルが保存されているファイルパスから記載が必要です。 #df = pd.read_csv(r'\\kyoyu_folder\section\name\data\test.csv') 指定の一例 df.loc[[0,4],['年月日','時刻コード']] #行名、列名を指定 #df.iloc[[0,4],[0,1]] 番号で指定することもできます。 |
実行結果
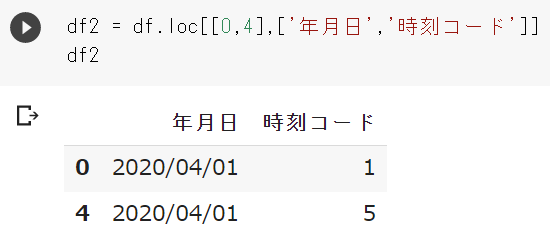
df.locでは行名・列名で指定する必要がありますが、df.ilocでは行番号・列番号で指定することができます。
この方法では指定した行や列は連続していなくても問題ありません。
指定した列の内、指定した行のデータを取ることができます。
1つ1つ列名と行数を指定することで、1~5列目の1~10行目のように連続する列や行を指定することもできますが、もう少し楽な方法を次の項目で紹介します。
指定範囲の行・指定範囲の列をまとめて取得
Excelで言う範囲選択のように、例えば1行目~10行目かつ1列目~5列目までの範囲にあるデータをまとめて取得したいときはこちらです。
|
1 2 |
df.loc[1:10,'時刻コード':'システムプライス(円/kWh)'] 行と列をインデックスで指定 #df.iloc[1:10,1:5] 行と列を数字で指定 |
実行結果
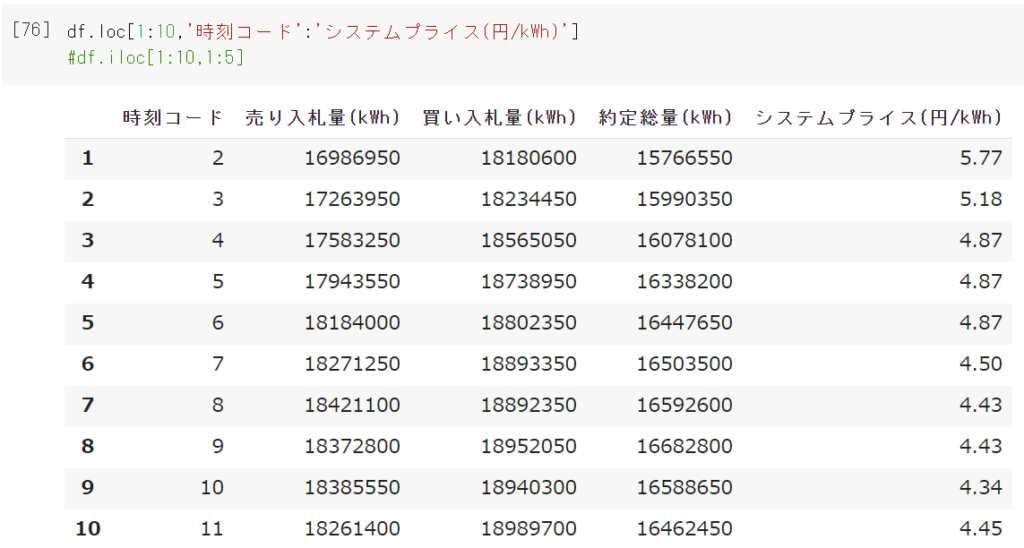
Pythonのスライス機能([1:10]のようにコロンを使って範囲を指定)を使うことで、連続する範囲を指定して取得することができます。
まとめ
今回は複数行・複数列のデータをまとめて取得する方法を確認しました。
次の記事:groupbyでデータをまとめる
前の記事:行列を指定して特定のデータを取得
Pandasについての公式なWebページです。
こちらは全て英語なので、日本語で体型的に学習するのであれば書籍が効率的です。
Pandasの基本的な使い方を辞書的に調べることができます。

業務でのデータ分析など、実践的なPandasの使い方まではこの本ではかばーしていないため、別途調べる必要があります。
しかし、実務で活用するための基礎的な内容がまとめられているので、遅かれ早かれ必要になります。どのようなコマンドがあるかをざっと目を通しておくだけでも良いので確認すると役に立ちます。

コメント