
Numpyの基礎的なコマンドをまとめました。
- Numpyをインポート
- ベクトルの作成
- ベクトルの中身を表示
- 行列を作成
- 行列の中身を表示
- 行列の要素を取得
- 型を調べる
- データ型を調べる
- データ型の指定
- データ型の種類
- 行列の演算
- ブロードキャスト
- 行列の形を確認
- 行列の形を変更
- 次元の追加
- 次元の削除
- 1次元に変換
- スライス
- 等差数列の作成(ステップ値で区切る)
- 等差数列の作成(区切り回数を指定)
- 全要素が0の配列を作成
- 全要素が1の配列を作成
- 単位行列の作成
- 乱数を作成
- 同じ乱数を生成:np.random.seed(0)
- 標準正規分布に従う乱数を作る:np.random.randn()
- 任意の正規分布から乱数を生成する
- 最小値・最大値・行列のサイズを指定して配列を作成
- 配列の形状変更
- 指定した範囲内でランダムに値を取得
- In-Place処理
- ビュー
- 配列のコピー:copy()
- ソートされたインデックスを取得:argsort()
- 編集予定
Numpyをインポート
|
1 |
import numpy as np |
ベクトルの作成
|
1 2 |
x = np.array([1,2,3,4]) #以降この変数を使用していきます。 |
ベクトルの中身を表示
|
1 2 3 4 |
x #結果:array[1,2,3,4] print(x) #実行結果:[1 2 3 4] |
行列を作成
|
1 2 |
y = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]]) #以降この変数を使用していきます。 |
行列の中身を表示
|
1 |
y |

|
1 |
print(y) |

行列の要素を取得
|
1 2 3 |
y[2,3] #インデックスが2,3の要素を取得(3行4列目の要素) #結果:12 |
型を調べる
|
1 2 3 4 5 6 7 8 9 |
type(x) #結果:numpy.ndarray type(y) #結果:numpy.ndarray type(x[0]) #結果:numpy.int64 type(y[0][-]) #結果:numpy.int64 |
データ型を調べる
array.dtypeでデータ型を調べることができます。
|
1 2 3 4 |
list = [1,2,3,4,5] array = np.array(list,int32) print(array.dtype) #int32 |
データ型の指定
numpy配列作成時などに引数でデータ型を指定することができます。
|
1 2 3 4 5 6 7 8 9 |
z = np.array([1,2,3,4], dtype = float) z #結果:array([1., 2., 3., 4.]) print(type(z)) #結果:<class 'numpy.ndarray'> type(z[0]) #結果:numpy.float64 print(type(z[0])) #結果:<class 'numpy.float64'> |
データ型の種類
int8,int16,int32,int64(符号付き整数)
float8,float16,float32,float64(浮動小数点数)
unit8,unit16,unit32,unit64(符号なし整数)
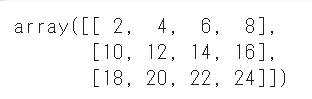
行列の演算
|
1 2 3 |
a = np.array([[1,2,3,4][5,6,7,8],[9,10,11,12]]) b = np.array([[1,2,3,4][5,6,7,8],[9,10,11,12]]) a+b |
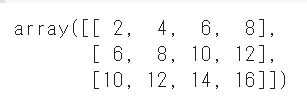
ブロードキャスト
|
1 2 3 4 5 |
a = np.array([1,2,3,4]) b = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]]) #aの要素がbに対して少ないが、自動で要素を加えて計算する #この場合aは([1,2,3,4],[1,2,3,4],[1,2,3,4])になる a + b |
行列の形を確認
numpy配列が何行何列でできているかを確認します。
|
1 2 3 4 5 6 7 |
x.shape x = np.array([1,2,3,4]) y = np.array([[1,2],[3,4]]) x.shape #(4,) y.shape #(2,2) 2行1列 |
行列の形を変更
x行y列のnumpy配列を指定した行列数に変えます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
x.reshape(1,4) #array([[1, 2, 3, 4]]) x.reshape(4,1) #array([[1], # [2], # [3], # [4]]) x.reshape(2,2) #array([[1, 2], # [3, 4]]) x.reshape(2,3) #これはエラー |
次元の追加
|
1 2 3 4 5 6 7 |
x = np.array([1,2,3,4]) x = x.shape ex_x = np.expand_dims(x, axis=0) ex_x.shape #(1,4) 最初に次元を追加 ex_x = np.expand_dims(x, axis=-1) #(4,1) 最後に次元を追加 |
次元の削除
|
1 2 3 4 |
np.squeeze() x = np.array([[1,2,3],[4,5,6]]) sq_x = np.squeeze(x) print(np.squeeze(x)) |
1次元に変換
|
1 2 3 |
x = np.array([[1,2,3,4],[5,6,7,8,]]) x.flatten() #array([1, 2, 3, 4, 5, 6, 7, 8]) |
スライス
|
1 2 3 4 5 6 7 8 9 10 11 12 |
x = np.array([1,2,3,4,5]) x[:] #array([1, 2, 3, 4, 5]) x[0:2] #array([1, 2]) x[:-1] #array([1, 2, 3, 4]) #対応関係 #[ 1, 2, 3, 4, 5] #[ 0, 1, 2, 3, 4] #[-5,-4,-3,-2,-1] |
等差数列の作成(ステップ値で区切る)
|
1 2 3 4 5 6 |
np.arange(1,5,1) #array([1, 2, 3, 4]) 1から4まで1ずつ刻んで配列を作成 np.arange(2,10,2) #array([2, 4, 6, 8]) 2から9まで2ずつ刻んで配列を作成 np.arange(20,1,-5) #array([20, 15, 10, 5]) 20から2まで5ずつ刻んで降順で配列を作成 |
等差数列の作成(区切り回数を指定)
|
1 2 |
np.linspace(1,10,4) #array([ 1., 4., 7., 10.]) 1から10までを4つの区間で等間隔に区切って配列作成 |
|
1 2 |
np.logspace(1,10,10, base=2) #array([ 2., 4., 8., 16., 32., 64., 128., 256., 512., 1024.]) |
全要素が0の配列を作成
|
1 2 3 4 |
shape = (2,2) np.zeros(shape) #array([[0., 0.], # [0., 0.]]) |
全要素が1の配列を作成
|
1 2 3 4 |
shape = (2,2) np.ones(shape) #array([[1., 1.], # [1., 1.]]) |
単位行列の作成
|
1 2 3 4 |
np.eye(3) #array([[1., 0., 0.], # [0., 1., 0.], # [0., 0., 1.]]) |
乱数を作成
|
1 2 3 4 5 |
np.random.rand() #0.5635904641473948 np.random.rand(2,2) #引数で行列数を指定 #array([[0.89705313, 0.22678426], # [0.75007746, 0.4958645 ]]) |
同じ乱数を生成:np.random.seed(0)
|
1 2 3 4 5 6 7 8 9 10 11 12 |
np.random.seed(0) np.random.rand() #0.417022004702574 np.random.seed(1) np.random.rand() #0.54881・・・ np.random.seed(0) #引数が同じであれば何度実行しても同じ乱数になる。 np.random.rand() #0.417022004702574 np.random.seed(1) #引数が同じであれば何度実行しても同じ乱数になる。 np.random.rand() #0.54881・・・ |
引数の数字は0でなくても良い。
np.random.randなどで乱数を発生させる前には、都度np.random.seed()を実行する。
引数を変えることで発生する乱数は変わるため、引数を指定することで常に複数の同じ乱数を発生させることができる。
標準正規分布に従う乱数を作る:np.random.randn()
|
1 2 3 4 |
np.random.randn() #-1.057952218862339 np.random.randn(1,2) #array([[-0.10894803, -0.6942068]]) |
np.random.randn()で平均0、分散1の標準正規分布に従う乱数を作ることができます。
引数で行列数を指定することができます。
任意の正規分布から乱数を生成する
|
1 2 3 4 |
mu = 0 sigma =2 np.random.normal(mu, sigma) #-1.8180152298536987 |
最小値・最大値・行列のサイズを指定して配列を作成
|
1 2 3 4 5 6 7 8 |
size = (5,5) np.random.randint(1,10,size=size) #array([[5, 6, 8, 4, 7], # [5, 4, 8, 7, 2], # [4, 6, 9, 5, 7], # [4, 3, 1, 5, 3], # [5, 2, 8, 9, 3]]) #5行5列で1から10までの要素からなる行列を作成 |
配列の形状変更
変更前と変更後の配列の要素数が異なる場合に用いる。
変更後の要素数の方が少ない場合は後ろの要素は削られる。
変更後の方が要素数が多い場合は0で埋められる。
|
1 2 3 4 |
np.random.seed(0) num = np.random.randint(5,10) array = np.random.rand(num) array.resize(5,5) |
指定した範囲内でランダムに値を取得
|
1 2 3 4 |
x = np.arange(1,100,1) np.random.choice() #16 #1から99まで1ずつ刻んだ配列を作り、その範囲内でランダムで値を生成 |
In-Place処理
対象の配列を直接編集すること。メモリを節約する。
|
1 2 3 4 5 |
np.array = [2,1,3] np.array_2 = [] np.array_2 = np.array.sort() #[1] np.array_2には代入されない。 print(np.array, np.array_2) #[1,2,3],None |
[1]
.sort()はIn-Place処理であるため、np.array_2にはソートされたnp.arrayは代入されず、np.arrayが直接ソートされます。
その次のprint関数でもnp.arrayとnp.array_2を出力すると、ソートされた結果である[1,2,3]とNoneが出力されています。
ビュー
あるnumpy配列を別のnumpy配列に代入し、
一方の配列の要素を変更すると、もう一方も変更されます。(配列が3つ以上でも同様です。)
ビューが作成され、元のnumpy配列をメモリを共有していることが理由です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
np.array = [1,2,3] array1 = np.array array1[0] = 99 print(array1,np.array) #[99,2,3] [99,2,3] np.array2 = [2,3,4] array2 = np.array2 array_2 = array2 #3つ目の配列 array_2[0] = 99 print(array_2,array2,np.array2) #[99,3,4] [99,3,4] [99,3,4] #3つ目の配列もビューが作成されている |
配列のコピー:copy()
配列をコピーするcopy()を用いることで、メモリを共有せずに別の配列として作成することができます。
これにより、一方で要素を変更してももう一方には影響がありません。
ソートされたインデックスを取得:argsort()
argsort()を用いることで、対象のnumpy配列について値が小さい順にインデックスを取得することができます。
|
1 2 3 4 5 6 7 |
array = np.array([3,2,1]) array2 = array.argsort() print(array2) #array([2,1,0], dtype=int64) [1] #[2,1,0]は値の小さい順番でインデックスが出力されている。 print(array[2],array[1],array[0]) #1 2 3 |
[1]
コード例のように、array([2,1,0] , dtype=int64)とありますが、これは値の小さい順にインデックスが表示されています。
元のnumpy配列が[3,2,1]なので、確かに逆からインデックスを見ると[2,1,0]であり、値が小さい順になっています。
編集予定
|
1 |
np.sqrt() |
|
1 |
np.log() |
|
1 |
np.exp() |
|
1 |
np.e |
|
1 |
np.sum |
|
1 |
np.sum |
|
1 |
np.abs() |
|
1 |
np.nan |
|
1 |
np.isnan() |
|
1 |
np.clip() |
|
1 |
np.clip() |
|
1 |
np.where() |
|
1 |
np.unique() |
|
1 |
np.unique(array, return_counts=True) |
|
1 |
np.bincount() |
|
1 |
np.concatenate() |
|
1 |
np.stack() |
|
1 |
np.transpose() |
|
1 |
np.save('path', array) |
|
1 |
np.load('path') |

コメント