
Pandasの基本的な使い方をこの記事でまとめています。
PandasはExcelの操作から機械学習まで、応用の範囲はかなり広いです。
多くの使い方があるため覚えるのは大変ですが、使いこなすことができれば非常に役に立つ武器になります。
この記事で紹介する操作は、それぞれ独立してサンプルコードを付けています。
各サンプルコードをコピペして使うことができますし、組み合わせて使う場合はimportなど重複する内容は必要に応じて省いてください。
DataFrame(データフレーム)の作成
PandasのDataFrame(行列)を作成することができます。
|
1 2 3 4 5 6 7 8 9 10 11 |
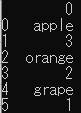
import pandas as pd df_1 = pd.DataFrame([1,2,3,4,5]) print(df_1) df_2 = pd.DataFrame(["apple","orange","grape"]) print(df_2) data = ["apple",3,"orange",2,"grape",1] df_3 = pd.DataFrame(data) print(df_3) |
df_1
![]()
df_2

df_3
1列のみのDataFrameを作成することもできます。
DataFrameをはじめから作るよりも、もともと持っているデータを読み込むことの方が多いかとは思いますが、pandasを使い始めの頃はいろいろと使い方を試すにあたって、小さなDataFrameを作って実験してみると理解が深まるので、覚えておいて損はありません。
Series(シリーズ)の作成
PandasのSeries列を作成します。
SeriesはDataFrame(行列)に新たな列として追加することができます。
DataFrameにもともと存在する列を指定してデータを書き込むこともできます。
|
1 2 3 4 5 |
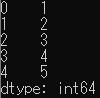
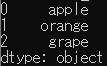
import pandas as pd series_1 = pd.Series([1,2,3,4,5]) print(series_1) series_2 = pd.Series(["apple","orange","grape"]) print(series_2) |
series_1
series_2
Excelファイルを読み込む
Excelファイルとして保存
CSVファイルとして読み込む
グループ化
groupby:グループ化
|
1 2 |
df.groupby('カラム名') # df.groupby('...').mean() |
groupbyを使っただけでは実行しても何も表示されない。
ただし、コメント部分のように平均値などを取って実行すると結果が表示される。
表の結合
pd.concat([df1,df2])
|
1 2 |
pd.concat([df1,df2]) pd.concat([df1,df2], axis = 1) |
df1の下にdf2が結合される。
df1にないカラムはdf2ではNaNと表示される。逆も同様。
2行目ではdf1の横にdf2が結合される。
.merge():同じカラムをKeyに結合する
|
1 |
df1.maerage(df2) |
df1とdf2に同じカラムをキーにして結合する。
pd.concat()では同じカラムがあってもそのまま結合するため、重複するカラムが発生する。
.mearge()では同じカラムがあれば重複なしで結合される。
df1.merge(df2, how=’…’):
|
1 2 3 4 5 |
df1.merge(df2, how = 'inner') df1.merge(df2, how = 'inner') df1.merge(df2, how = 'left') df1.merge(df2, how = 'right') df1.merge(df2, left_on ='カラム名', right_on = 'カラム名') |
innerは同じキーがある場合のみ結合し、それ以外は捨てる。
outerは同じキーの有無にかかわらず結合する。結合できなかった部分はNaNになる。
left,rightはdf1の左、右のどちら側に結合するかを指定する。
left_on、right_onを使用すると、df1とdf2で共有するキーを指定することができる。
.join():複数の表をまとめて結合
|
1 |
df1.join([df2, df3]) |
df1に対して、df2,df3のデータフレームを一度の操作で結合することができる。
ユニークな(重複のない)値を表示・取得
.unique():ユニークな値のみ表示
|
1 |
df['カラム名'].unique(): |
Seriesに対してのみ使用できる。
.nunique():ユニークな値の数を表示
|
1 |
df['カラム名'].unique(): |
Seriesに対してのみ使用できる。
それぞれの値にいくつレコードがあるかを取得
df.value_counts()
|
1 |
df['カラム名'].value_counts(): |
DataFrame、Seriesの両方に対して実行できる。
ソート
df.sort_values(‘カラム名’)
|
1 2 |
df.sort_values('カラム名') df.sort_values('カラム名', ascending = False) |
指定したカラム名でソートすることができる。引数の指定をしない場合、昇順(小さい値から)でソートされる。
2行目で、ascending=Falseとすることで降順(大きい値から)に変更することができる。
Seriesの各要素に関数を実行する
df.apply()
|
1 |
df['カラム名'].apply('関数名') |
関数を作成した上で、カラム名を指定し、.apply(‘関数名’)と入力して実行することで、
指定したカラムの各要素に対して関数を実行し、その結果をSeriesで返すことができる。
df.iterrows()
|
1 |
df['カラム名'].apply('関数名') |
DataFrameをCSVとして保存
df.to_csv(‘path\filename.csv’)
|
1 |
df.to_csv('ファイルパス\ファイル名.csv', index=False) |
Index=Falseにすることでインデックス(行番号)を除外して保存することができる。

コメント