
この記事では文字コードについての概要を整理する。
PythonやVBAからExcelファイルやCSVファイルへの出力や、
読み込み時に文字コードに絡んだエラーが発生することがあるが、
Webで適当に検索して何となく解決して完了とするのではなく、
文字コードについておさらいすることでエラーの裏で何が起こっているかについて知り、
意味を理解したうえで対応ができることを目的とする。
内容に誤りを含む可能性があうので、厳密な理解は専門の書籍や解説記事をご確認ください。
文字コードとは
文字コードとはコンピュータがテキストデータをエンコード(符号化)またはデコード(複合化)するための規則や方式を指す。
文字コードを使う理由は、コンピュータが0と1しか認識できないことにある。
コンピュータは人間のように文字を認識することはできないため、人間が使う文字に数値を割り当てて扱うことで、コンピュータ上で文字を表現できるようにした。
文字コードは、実際には2つの考え方と数値の振り方によって構成されている。
符号化文字集合
ASCIIやUnicodeなどが符号化文字集合に該当する。
UTF-8,SHIFT-JIS,CP932は符号化文字集合ではない。
符号化文字集合では、1文字ごとに固有の数字を割り当てる。
“A”という文字はASCIIでは65。
UnicodeではU+0041が割り当てられている。
符号化文字集合で割り当てられた数字は、コンピュータが実際に扱う数字ではない。
単純に先頭から何番目にあるかのような、位置情報を示すための数字。
※実際にどのように割り振られているかはそれぞれの規則を確認してください。
ASCIIの文字コード表
ASCIIの文字コード表は以下の通り
以下のように3列で1つの組み合わせになっているものが、横に8つ並んでいる
文字 | 10進数での表記 | 16進数での表記 ・・・
文字”A”は2行目・14列目の位置にある。
“A”の1つ右にある10進数の列を見ると65と記載されているので、
“A”は10進数表記では65で示されることが見て取ることができる。
左の9列までは特殊な文字が多い。
空文字、タブなどに加えて、TCP/IPを勉強していると出てくるような表現もある。
異なるコンピュータの間で通信をするために、通信に必要な情報を示す文字などもコード表に入れる必要があったのではないかと想像しています。
“NUL”は空文字
“SOH”は文字の開始位置など。。。
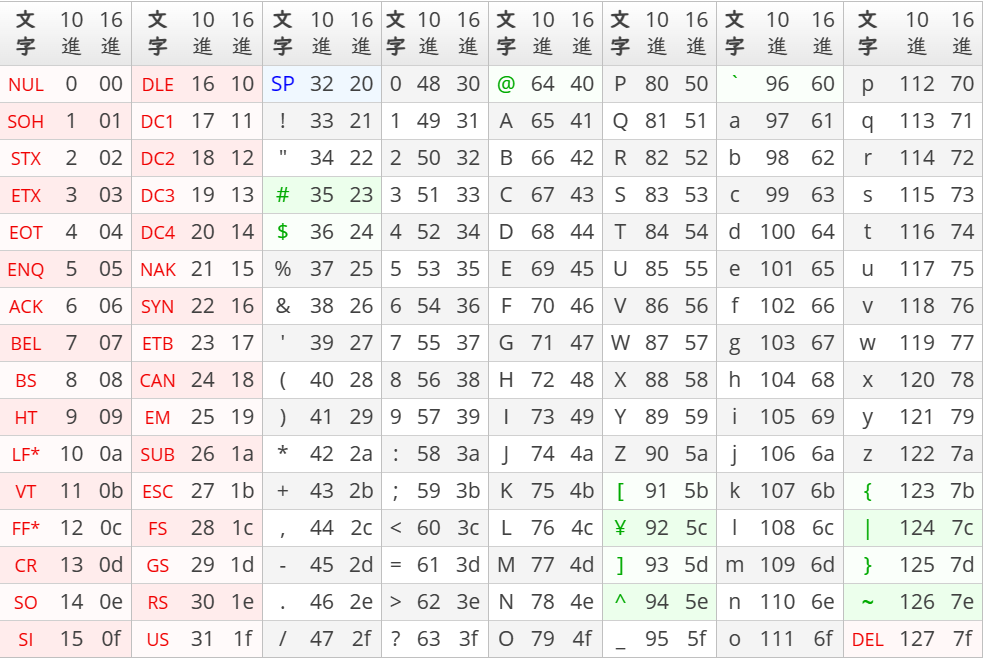
※こちらから抜粋:ASCIIコード表 – IT用語辞典 e-Words
文字コード表は作成者によって構成が違うことがある。
Unicodeの文字コード表
世界中の文字をUnicodeで表現しようとしているので、割り当てに使用する数値も大きくなっている。Unicodeは16進数を使って各文字に数値を割り当てている。
Wikipediaの文字コード表では、以下のように見て取ることができる。
文字”A”は5行目、2列目にある(一番上・一番左は除いて数えている)ので、
Unicodeの文字コード表では文字”A”は、 U+0041として表現される。
0040までは行名、最後の1桁は列名に記載されている数字を用いている。
先頭のUはUnicodeであることを示す文字。
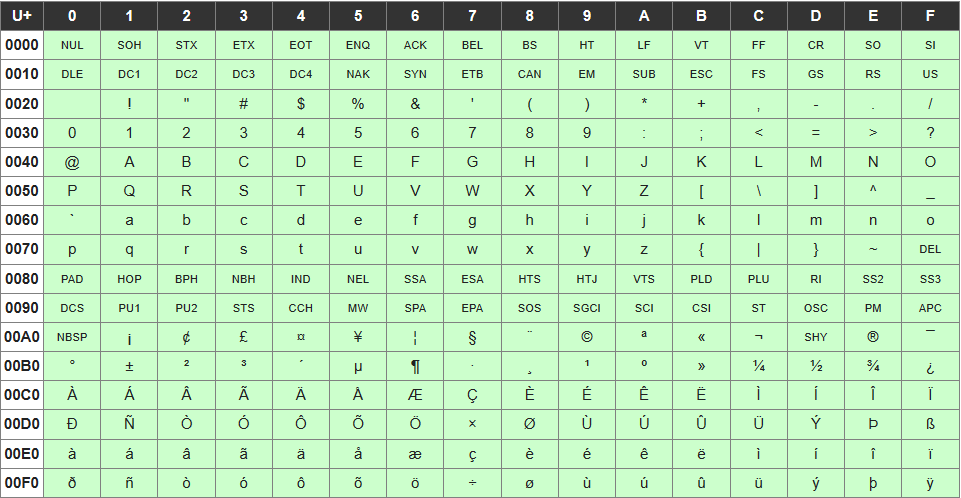
※Wikipediaから一部を抜粋
文字符号化方式
文字符号化方式は、文字列データをコンピュータが扱える数値(バイト表現)に変換する方式を指す。
符号化文字集合で1文字ごとに数値が割り振られ、その数値をさらにコンピュータが扱える数値に再度変換するために使われる。
ASCIIでは符号化文字集合に割り当てられている数値をそのままコンピュータが扱うことができるので意識する必要はないが、他の文字符号化方式では上記のように2段階で文字から数値に変換を行っている。
UTF-8、SHIFT-JIS、CP932などが文字符号化方式に該当する。
UTF-8はUnicodeの符号化文字集合を数値に変換するための方式、
文字によって使用するバイト数が異なる。英語のみで構成されたASCIIで対応している文字は1バイト(8ビット)でエンコードされ、ラテン文字やギリシャ文字などは2バイトでエンコードされる。
UTF-16は基本的には2バイト(16ビット)でエンコードされる。一部の文字は4バイトで表現される
UTF-32は4バイトでエンコードされるが、1バイトで表現できる文字に対しても4バイトで表現することになり、無駄がある。
SHIFT-JISはJISが定めたJIS X 0208という符号化文字集合を数値に変換するための方式。
JISは日本の規格を定める団体で、日本語を扱うためにSHIFT-JISは定められたが、海外では無視されることもある。
JIS X 0208では、各ベンダーが自由に文字列に対して数値を割り当てることができる部分があった。
そのため、ベンダーごとに割り当てられている数値(まだコンピュータが扱えない段階)が異なるという問題があった。
そこで、マイクロソフトがWindows-J31という名前で文字符号化方式を規定し、NECやIBMが独自に拡張していたCP932を統合し、現在のCP932(MS932とも呼ばれる)となっている。
Pythonで文字コードを扱う
Pythonで文字コードを扱ってみる。Unicodeを用いる。
エンコード
|
1 2 3 |
#"A"をutf-8で16進数にエンコード "A".encode('utf-8').hex() #41 Unicodeコード表では+U0041と表記される |
デコード
|
1 2 |
print("\u0041") #A Unicodeの+U0041から文字Aを表現。 |
pandasで特殊文字をCSVに出力する
Pythonでpandasを使ってデータフレームをCSVに出力する際、
“df.to_csv(“ファイル名”, encoding=”shift-jis”)”といった記述をするが、
shift-jisでは、髙(はしごだか)などの特殊文字がエンコードできない。
そこで”df.to_csv(“ファイル名”, encoding=”cp932″)”とすることでエンコードできる。

コメント